
ㅁ 개요
이 장의 목표는 와인 데이터의 속성(성분 등)을 분석한 뒤 셈플 데이터를 이용하여 품질 등급을 예측하는 것이다. 이를 위해 데이터의 선형회귀분석 기술 통계를 구하고 레드와인과 화이트 와인 그룹의 품질에 대해 t-검정으로 셈플와인의 품질을 예측하는 내용입니다. 와인속성에 따른 품질 등급을 예측하기 위해 와인의 속성을 독립변수로 정하고, 와인의 품질을 종속 변수로 선형 회귀분석을 수행한다.
셈플데이이터는 캘리포니아 어바인 대학의 머신러닝 저장소의 자료를 다운받아 활용합니다.
ㅁ 핵심 개념
- 기술통계 : 요약통계(평균(mean), 중앙값(median), 최빈값(mode))로 대표값을 찾고 표준편차(standard deviation)과 사분위(quartile)로 분포를 확인할 수 있습니다.
- 회귀분석(regression analysis) : 독립변수 x와 종속변수 y간의 상호 연관성 정보 파악하는 분석기법입니다. 하나의 독립변수에 따라 종속변수가 어떻게 변하는지 측정하는 것으로 변수 간의 인과관계를 분석할 때 사용합니다.

* 위키백과 정의 : https://ko.wikipedia.org/wiki/%EC%84%A0%ED%98%95_%ED%9A%8C%EA%B7%80
- t - 검증 : 데이터에서 찾은 평균으로 두 그룹에 차이가 있는지 확인하는 방법입니다.

- 히스토그램 : 데이터값을 몇 개 구간으로 나누고 각 구간에 해당하는 값의 숫자나 상태적 빈도 크기를 차트로 나타낸 것입니다. 파이썬의 matplotlib 라이브러리 hist(), seaborn 라이브러리 패키지의 distplot()함수를 활용합니다.
ㅁ 실습 준비
실습에 앞서 환경구성을 위해 코랩 마운트를 시행합니다. 마운터 경로는 다음으로 지정합니다.
마운트 경로 /content/drive/MyDrive/Colab Notebooks/
from google.colab import drive
drive.mount('/content/drive')- 데이터 수집
https://archive.ics.uci.edu/ml/datasets.phphttps://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/
UCI Machine Learning Repository: Data Sets
archive.ics.uci.edu
- 라이브러리 준비
필요한 라이브러리는 엑셀 작업을 위해 Pandas입니다. 그리고, 분석이 끝난후 시각화는 matplotlib 라이브러리를 활용합니다.
ㅁ 코드 작성
import pandas as pd
red_df = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/winequality-red.csv", sep=';', header=0)
# 기존에 작성형식을 마운트하면 위와 같이 경로를 변경하여 줍니다. red_df = pd.read_csv("/winequality-red.csv")
red_df.head()
# 이 명령을 수행하면, red_df 상위 5개의 자료만 출력됩니다.
# 실행결과는 다음과 같습니다. white_df 도 동일한 방법으로 메모리에 할당하고 확인할 수 있습니다.
ㅁ 데이터 병합하기
두개의 정보인 white, red _df 각각 type 컬럼을 추가합니다.
red_df.shape # 행, 열의 형태를 확인
- 레드, 화이트와인 두개의 엑셀을 하나의 엑셀로 합하기
wine = pd.concat([red_df, white_df])ㅁ 화인 그룹별 품질 확인
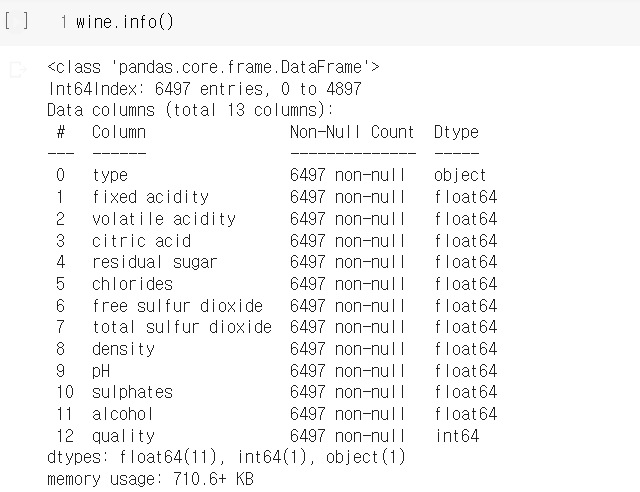
ㅁ 함수를 사용해 기술 통계 구하기
함수를 사용해 기술 통계를 구하기 위해서는 파이썬 Pandas 패키를 활용합니다.

wine.groupby('type')['quality'].mean()

ㅁ 데이터 모델링
품질 등급을 예측하기 위한 분석 모델을 만들어 봅시다.
이를 위해 함수를 사용해 기술 통계를 구하기 위해서는 파이썬 statsmodels 라이브러리를 활용합니다.
6.1 dessribe()함수를 사용해서 그룹별로 갯수, 평균, 표준편차 등을 구하기
구할 내용은
6.2 t-검증과 회귀 분석으로 그룹 비교하기
- t- 검증을 위해 필요한 라이브러리 : scipy 라이브러리 패키지
- 회귀분석 : statsmodels 패키지
!pip install statsmodels # statsmodels 라이이브리 설치
wine.columns = wine.columns.str.replace(' ', '_') # wine 공백없애기
wine.to_csv('/content/drive/MyDrive/Colab Notebooks/wine2.csv', index = False) # wine.csv 만들기
Stats 라이브러리를 활용하기 위해 다음과 같이 소스를 불러옵니다.
from scipy import stats
from statsmodels.formula.api import ols # ordinary List Squares
참고 ) 최소자승법(OLS: Ordinary Least Squares)는 잔차제곱합(RSS: Residual Sum of Squares)를 최소화하는 가중치 벡터를 구하는 방법이다. 우리가 사용하는 예측 모형은 다음과 같이 상수항이 결합된 선형모형이다. https://namu.wiki/w/OLS
red_wine_quality = wine.loc[wine['type'] == 'red', 'quality']
white_wine_quality = wine.loc[wine['type'] == 'white', 'quality']
# T-검증 두 그룹간 차이 확인
stats.ttest_ind(red_wine_quality, white_wine_quality, equal_var = False)
# 문법 참고-> https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html
scipy.stats.ttest_ind — SciPy v1.8.1 Manual
Yuen, Karen K., and W. J. Dixon. “The Approximate Behaviour and Performance of the Two-Sample Trimmed t.” Biometrika, vol. 60, no. 2, 1973, pp. 369-374. JSTOR, www.jstor.org/stable/2334550. Accessed 30 Mar. 2021.
docs.scipy.org
# 선형회귀 분석 수행
# 독립변수에서 type는 red, white의 이산값으로 제외한 나머지 값들을 독립변수로 지정합니다.
Rformula = 'quality ~ fixed_acidity + volatile_acidity + citric_acid + \
residual_sugar + chlorides + free_sulfur_dioxide + \
total_sulfur_dioxide + density + pH + sulphates + alcohol'regression_result = ols(Rformula, data = wine).fit() # 선행회귀모델 최소자승법 시행
regression_result.summary() # 통계값 출력6.3 회귀 분석 모델로 새로운 샘플의 품질 등급 예측하기
sample1_predict과 wine[0:5]['quality'] #서로 비교하여 맞게 예측되었는지 확인한다.
- 임의의 값을 딕셔너리 형태로 만들기
sample2 # 출력하여 확인

https://link.coupang.com/a/rLhZT
퍼니트 리얼 몽모랑시 타트체리100%
COUPANG
www.coupang.com
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다
7. 결과 시각화
7.1 와인 유형에 따른 품질 등급 히스토그램 그리기
https://link.coupang.com/a/rMdOD
업무엔 편한 구두 슬리퍼!
착한구두 여성용 샌느 미들힐 뮬 슬리퍼 SDLTS2d179
COUPANG
www.coupang.com
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다
https://link.coupang.com/a/rA4dq
COUPANG
쿠팡은 로켓배송
www.coupang.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
'교육 > 파이썬빅데이터분석교육' 카테고리의 다른 글
| [파이썬통계분석]타이타닉호 침몰의 비밀, 1등석 고객의 생존가능성은? (0) | 2022.07.11 |
|---|---|
| 파이썬 동적 크룰링 실습_커피빈사이트 활용 (0) | 2022.07.04 |
| [파이썬]정적크룰링교안 (0) | 2022.06.16 |
| [파이썬 실습] 공공데이터 API 연동하여 출입국 정보 가져오기 (0) | 2022.06.08 |
| [파이썬]네이버API이용한 크룰링 활용 (0) | 2022.06.07 |